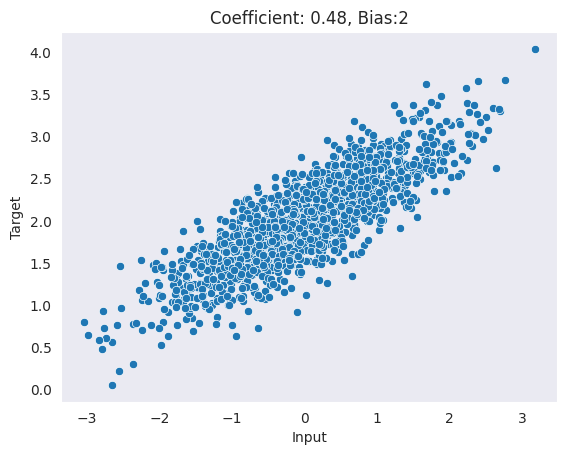
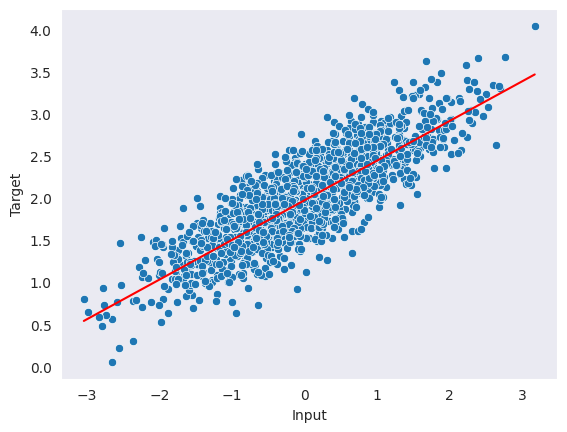
{'X': tensor([ 1.5328, 0.4394, 1.1542, -0.6743, 0.3194, -0.5863, 0.8216, -0.9489,
-1.5408, -1.0546, 0.9501, 0.3382, -0.0357, -0.4675, 0.7231, 0.9694,
0.8526, -1.4466, -1.0994, -1.2141, -0.7999, 1.3750, -1.1268, -0.7923,
0.0940, -0.1043, -0.0393, 1.2961, -0.4961, 1.0170, -0.6677, -0.7946,
0.9364, 2.5944, -0.2201, -0.5376, 1.6581, 0.2348, 0.5766, -1.6326,
0.0175, -0.3328, -1.7442, -1.4464, 0.1047, 0.0633, -0.5963, 0.7775,
-0.3005, -0.7565, -0.7994, -0.9605, 0.2461, -0.7047, 0.3769, 0.5410,
-0.6524, 1.5430, 1.0480, -0.5028, 1.3676, -0.2904, 0.2671, 1.3014]),
'y': tensor([2.2464, 2.5879, 2.7877, 1.5178, 2.2373, 1.9258, 2.1885, 2.2265, 1.4833,
1.4586, 2.7604, 2.4890, 1.9327, 1.5933, 2.4738, 2.4766, 2.4160, 1.3819,
1.4487, 0.8635, 1.4181, 2.8232, 1.2373, 2.0373, 1.7182, 2.0764, 2.1702,
2.8312, 1.7150, 2.3457, 1.9804, 1.5520, 2.5604, 3.3382, 1.9031, 1.2880,
2.9112, 1.9802, 2.0943, 1.3462, 2.0327, 1.9207, 1.2720, 1.8974, 2.5618,
2.4288, 2.0103, 2.5764, 1.4878, 1.6772, 1.6701, 1.5360, 2.3156, 1.7014,
2.3102, 2.1018, 2.4023, 2.0447, 2.8422, 1.3625, 2.6827, 1.9267, 2.1790,
2.7582])}