import torch, logging
## disable warnings
logging.disable(logging.WARNING)
## Import the CLIP artifacts
from transformers import CLIPTextModel, CLIPTokenizer
## Initiating tokenizer and encoder.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14", torch_dtype=torch.float16)
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14", torch_dtype=torch.float16).to("cuda")Stable diffusion using 🤗 Hugging Face - Looking under the hood
Stable Diffusion
An introduction into what goes on in the pipe function of 🤗 hugging face diffusers library
StableDiffusionPipelinefunction.
This is my second post of the Stable diffusion series, if you haven’t checked out the first one, you can read it here -
1. Part 1 - Introduction to Stable diffusion using 🤗 Hugging Face.
In this post, we will understand the basic components of a stable diffusion pipeline and their purpose. Later we will reconstruct StableDiffusionPipeline.from_pretrained function using these components. Let’s get started -

1 Introduction
Diffusion models as seen in the previous post can generate high-quality images. Stable diffusion models are a special kind of diffusion model called the Latent Diffusion model. They have first proposed in this paper High-Resolution Image Synthesis with Latent Diffusion Models. The original Diffusion model tends to consume a lot more memory, so latent diffusion models were created which can do the diffusion process in lower dimension space called Latent Space. On a high level, diffusion models are machine learning models that are trained to denoise random Gaussian noise step by step, to get the result i.e., image. In latent diffusion, the model is trained to do this same process in a lower dimension.
There are three main components in latent diffusion -
- A text encoder, in this case, a CLIP Text encoder
- An autoencoder, in this case, a Variational Auto Encoder also referred to as VAE
- A U-Net
Let’s dive into each of these components and understand their use in the diffusion process. The way I will be attempting to explain these components is by talking about them in the following three stages -
- The Basics: What goes in the component and what comes out of the component - This is an important, and key part of the top-down learning approach of understanding “the whole game”
- Deeper explanation using 🤗 code. - This part will provide more understanding of what the model produces using the code
- What’s their role in the Stable diffusion pipeline - This will build your intuition around how this component fits in the Stable diffusion process. This will help your intuition on the diffusion process
2 CLIP Text Encoder
2.1 Basics - What goes in and out of the component?
CLIP(Contrastive Language–Image Pre-training) text encoder takes the text as an input and generates text embeddings that are close in latent space as it may be if you would have encoded an image through a CLIP model.
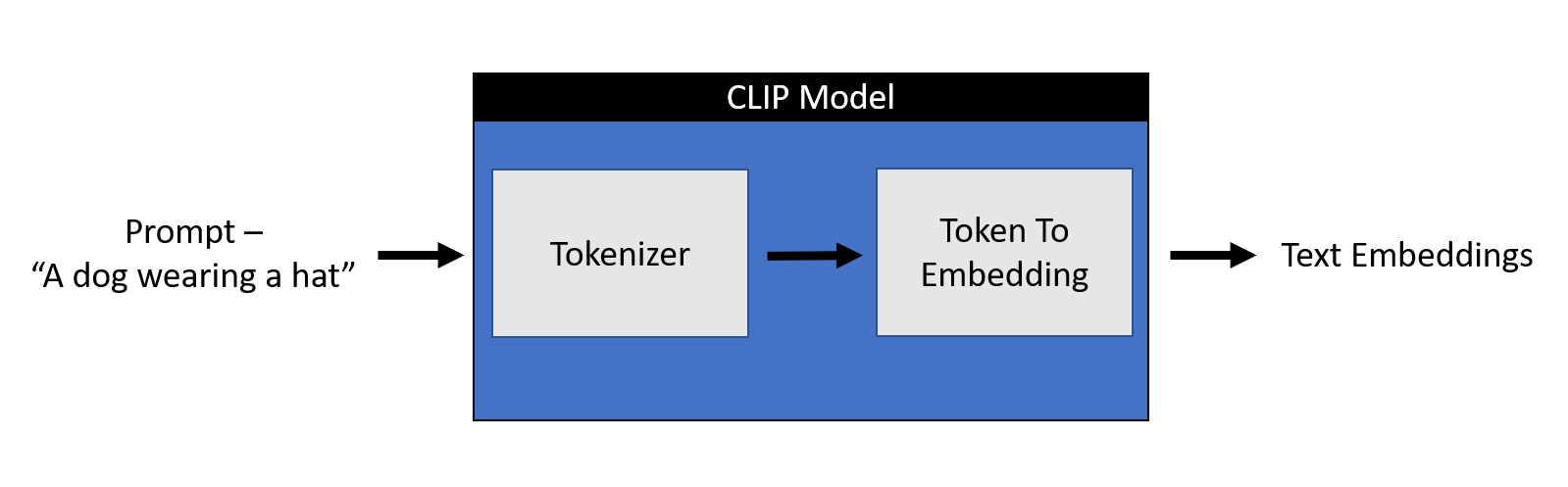
2.2 Deeper explanation using 🤗 code
Any machine learning model doesn’t understand text data. For any model to understand text data, we need to convert this text into numbers that hold the meaning of the text, referred to as embeddings. The process of converting a text to a number can be broken down into two parts -
1. Tokenizer - Breaking down each word into sub-words and then using a lookup table to convert them into a number
2. Token_To_Embedding Encoder - Converting those numerical sub-words into a representation that contains the representation of that text
Let’s look at it through code. We will start by importing the relevant artifacts.
Let’s initialize a prompt and tokenize it.
prompt = ["a dog wearing hat"]
tok =tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
print(tok.input_ids.shape)
toktorch.Size([1, 77]){'input_ids': tensor([[49406, 320, 1929, 3309, 3801, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]])}A tokenizer returns two objects in the form of a dictionary -
1. input_ids - A tensor of size 1x77 as one prompt was passed and padded to 77 max length. 49406 is a start token, 320 is a token given to the word “a”, 1929 to the word dog, 3309 to the word wearing, 3801 to the word hat, and 49407 is the end of text token repeated till the pad length of 77.
2. attention_mask - 1 representing an embedded value and 0 representing padding.
for token in list(tok.input_ids[0,:7]): print(f"{token}:{tokenizer.convert_ids_to_tokens(int(token))}")49406:<|startoftext|>
320:a</w>
1929:dog</w>
3309:wearing</w>
3801:hat</w>
49407:<|endoftext|>
49407:<|endoftext|>So, let’s look at the Token_To_Embedding Encoder which takes the input_ids generated by the tokenizer and converts them into embeddings -
emb = text_encoder(tok.input_ids.to("cuda"))[0].half()
print(f"Shape of embedding : {emb.shape}")
embShape of embedding : torch.Size([1, 77, 768])tensor([[[-0.3887, 0.0229, -0.0522, ..., -0.4902, -0.3066, 0.0673],
[ 0.0292, -1.3242, 0.3074, ..., -0.5264, 0.9766, 0.6655],
[-1.5928, 0.5063, 1.0791, ..., -1.5283, -0.8438, 0.1597],
...,
[-1.4688, 0.3113, 1.1670, ..., 0.3755, 0.5366, -1.5049],
[-1.4697, 0.3000, 1.1777, ..., 0.3774, 0.5420, -1.5000],
[-1.4395, 0.3137, 1.1982, ..., 0.3535, 0.5400, -1.5488]]],
device='cuda:0', dtype=torch.float16, grad_fn=<NativeLayerNormBackward0>)As we can see above, each tokenized input of size 1x77 has now been translated to 1x77x768 shape embedding. So, each word got represented in a 768-dimensional space.
2.3 What’s their role in the Stable diffusion pipeline
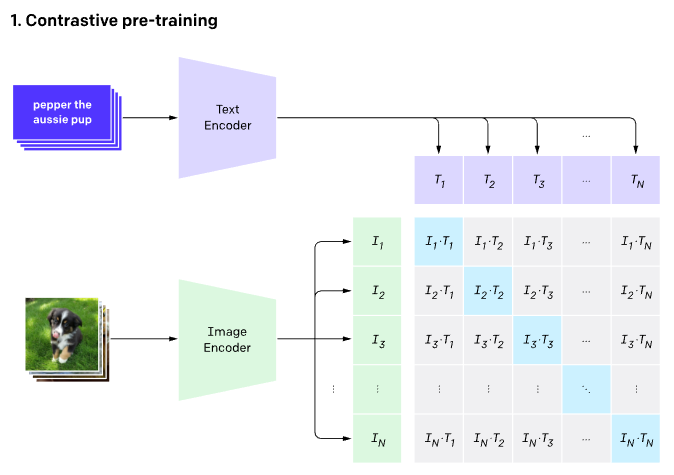
Stable diffusion only uses a CLIP trained encoder for the conversion of text to embeddings. This becomes one of the inputs to the U-net. On a high level, CLIP uses an image encoder and text encoder to create embeddings that are similar in latent space. This similarity is more precisely defined as a Contrastive objective. For more information on how CLIP is trained, please refer to this Open AI blog.
3 VAE - Variational Auto Encoder
3.1 Basics - What goes in and out of the component?
An autoencoder contains two parts -
1. Encoder takes an image as input and converts it into a low dimensional latent representation
2. Decoder takes the latent representation and converts it back into an image
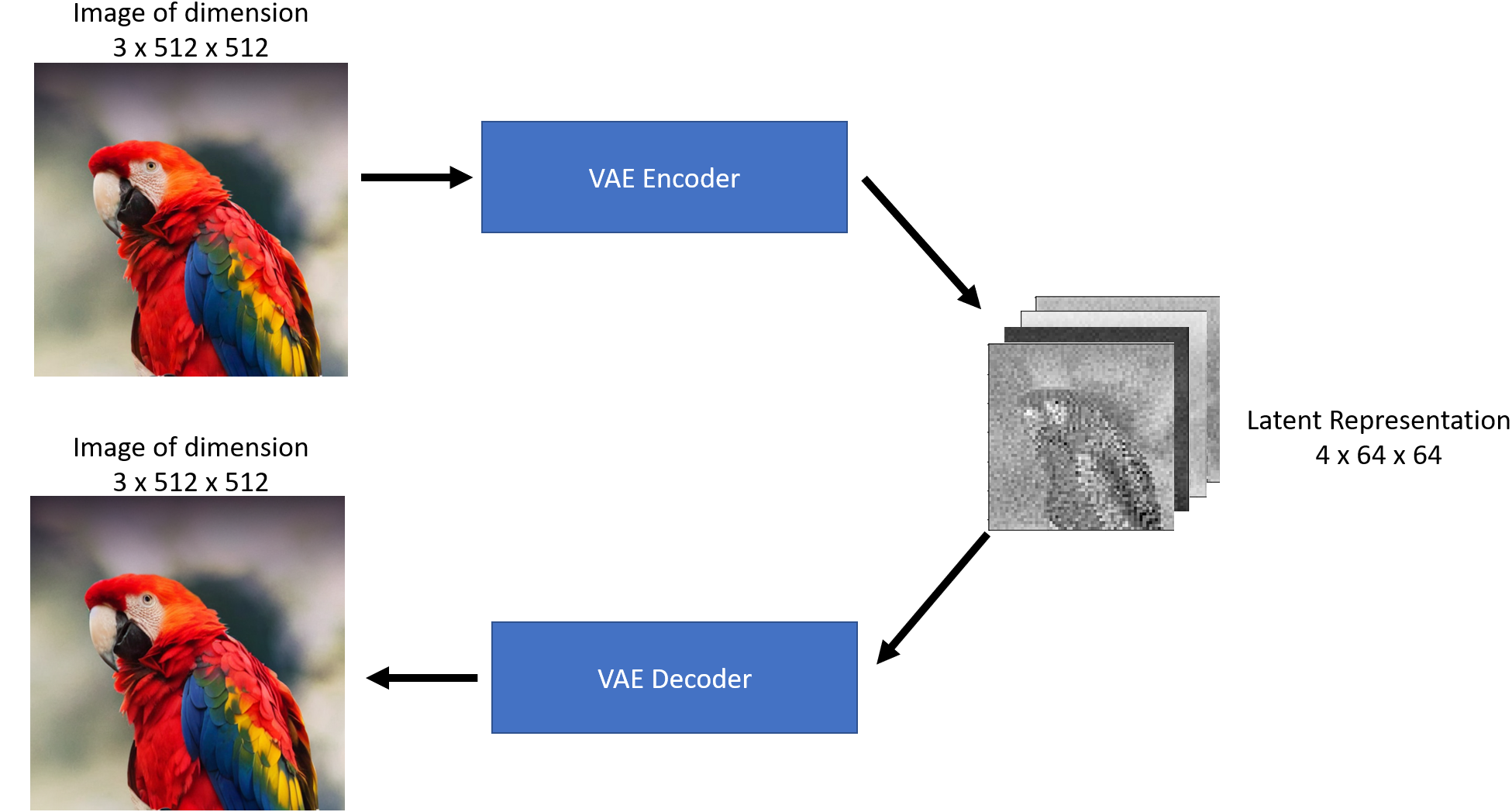
{kind=link}
As we can see above, the Encoder acts like a compressor that squishes the image into lower dimensions and the decoder recreates the original image back from the compressed version.
Note
Encoder-Decoder compression-decompression is not lossless.
3.2 Deeper explanation using 🤗 code
Let’s start looking at VAE through code. We will start by importing the required libraries and defining some helper functions.
Code
## To import an image from a URL
from fastdownload import FastDownload
## Imaging library
from PIL import Image
from torchvision import transforms as tfms
## Basic libraries
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
## Loading a VAE model
from diffusers import AutoencoderKL
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae", torch_dtype=torch.float16).to("cuda")
def load_image(p):
'''
Function to load images from a defined path
'''
return Image.open(p).convert('RGB').resize((512,512))
def pil_to_latents(image):
'''
Function to convert image to latents
'''
init_image = tfms.ToTensor()(image).unsqueeze(0) * 2.0 - 1.0
init_image = init_image.to(device="cuda", dtype=torch.float16)
init_latent_dist = vae.encode(init_image).latent_dist.sample() * 0.18215
return init_latent_dist
def latents_to_pil(latents):
'''
Function to convert latents to images
'''
latents = (1 / 0.18215) * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
return pil_imagesLet’s download an image from the internet.
p = FastDownload().download('https://lafeber.com/pet-birds/wp-content/uploads/2018/06/Scarlet-Macaw-2.jpg')
img = load_image(p)
print(f"Dimension of this image: {np.array(img).shape}")
imgDimension of this image: (512, 512, 3)
Now let’s compress this image by using the VAE encoder, we will be using the pil_to_latents helper function.
latent_img = pil_to_latents(img)
print(f"Dimension of this latent representation: {latent_img.shape}")Dimension of this latent representation: torch.Size([1, 4, 64, 64])As we can see how the VAE compressed a 3 x 512 x 512 dimension image into a 4 x 64 x 64 image. That’s a compression ratio of 48x! Let’s visualize these four channels of latent representations.
fig, axs = plt.subplots(1, 4, figsize=(16, 4))
for c in range(4):
axs[c].imshow(latent_img[0][c].detach().cpu(), cmap='Greys')
This latent representation in theory should capture a lot of information about the original image. Let’s use the decoder on this representation to see what we get back. For this, we will use the latents_to_pil helper function.
decoded_img = latents_to_pil(latent_img)
decoded_img[0]
As we can see from the figure above VAE decoder was able to recover the original image from a 48x compressed latent representation. That’s impressive!
Note
If you look closely at the decoded image, it’s not the same as the original image, notice the difference around the eyes. That’s why VAE encoder/decoder is not a lossless compression.
3.3 What’s their role in the Stable diffusion pipeline
Stable diffusion can be done without the VAE component but the reason we use VAE is to reduce the computational time to generate High-resolution images. The latent diffusion models can perform diffusion in this latent space produced by the VAE encoder and once we have our desired latent outputs produced by the diffusion process, we can convert them back to the high-resolution image by using the VAE decoder. To get a better intuitive understanding of Variation Autoencoders and how they are trained, read this blog by Irhum Shafkat.
4 U-Net
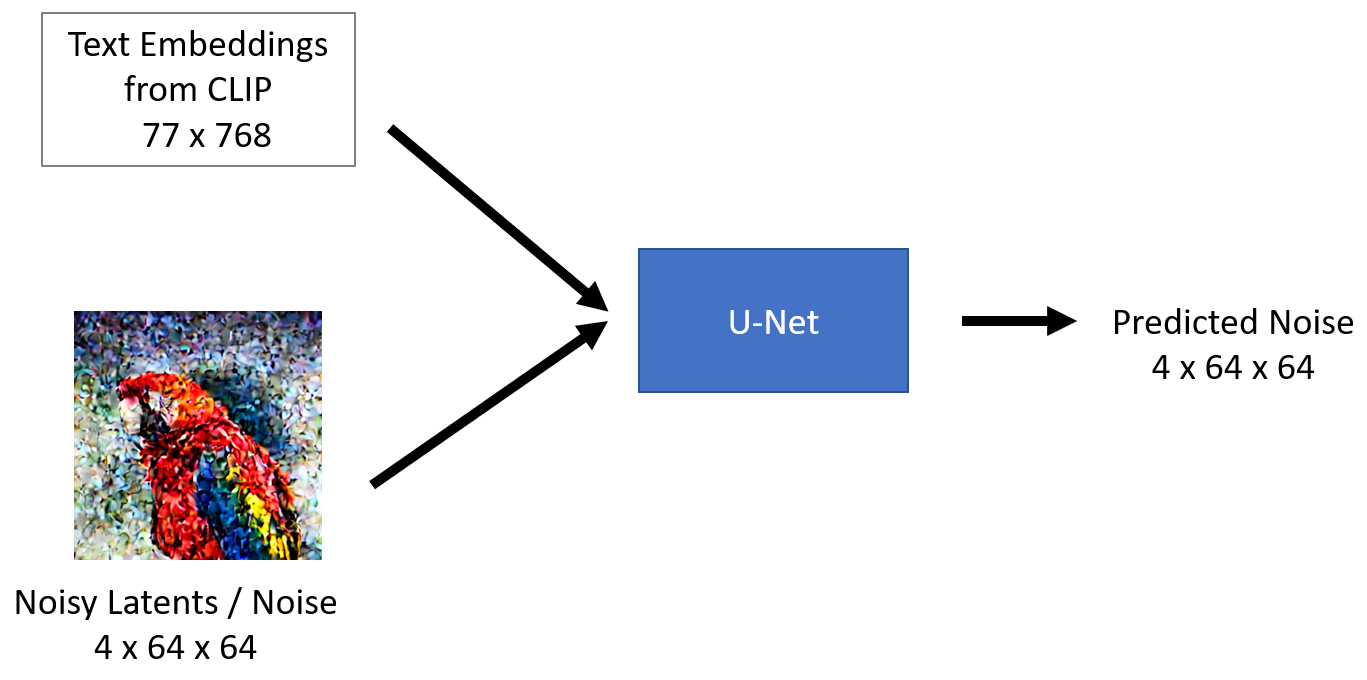
4.1 Basics - What goes in and out of the component?
The U-Net model takes two inputs -
1. Noisy latent or Noise- Noisy latents are latents produced by a VAE encoder (in case an initial image is provided) with added noise or it can take pure noise input in case we want to create a random new image based solely on a textual description
2. Text embeddings - CLIP-based embedding generated by input textual prompts
The output of the U-Net model is the predicted noise residual which the input noisy latent contains. In other words, it predicts the noise which is subtracted from the noisy latents to return the original de-noised latents.
4.2 Deeper explanation using 🤗 code
Let’s start looking at U-Net through code. We will start by importing the required libraries and initiating our U-Net model.
from diffusers import UNet2DConditionModel, LMSDiscreteScheduler
## Initializing a scheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
## Setting number of sampling steps
scheduler.set_timesteps(51)
## Initializing the U-Net model
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet", torch_dtype=torch.float16).to("cuda")As you may have noticed from code above, we not only imported unet but also a scheduler. The purpose of a schedular is to determine how much noise to add to the latent at a given step in the diffusion process. Let’s visualize the schedular function -
Code
plt.plot(scheduler.sigmas)
plt.xlabel("Sampling step")
plt.ylabel("sigma")
plt.title("Schedular routine")
plt.show()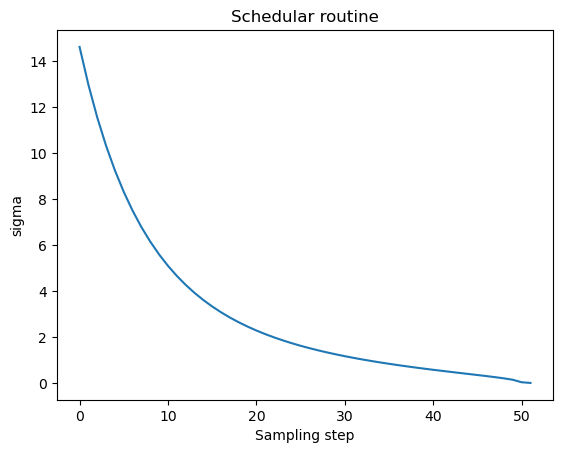
The diffusion process follows this sampling schedule where we start with high noise and gradually denoise the image. Let’s visualize this process -
Code
noise = torch.randn_like(latent_img) # Random noise
fig, axs = plt.subplots(2, 3, figsize=(16, 12))
for c, sampling_step in enumerate(range(0,51,10)):
encoded_and_noised = scheduler.add_noise(latent_img, noise, timesteps=torch.tensor([scheduler.timesteps[sampling_step]]))
axs[c//3][c%3].imshow(latents_to_pil(encoded_and_noised)[0])
axs[c//3][c%3].set_title(f"Step - {sampling_step}")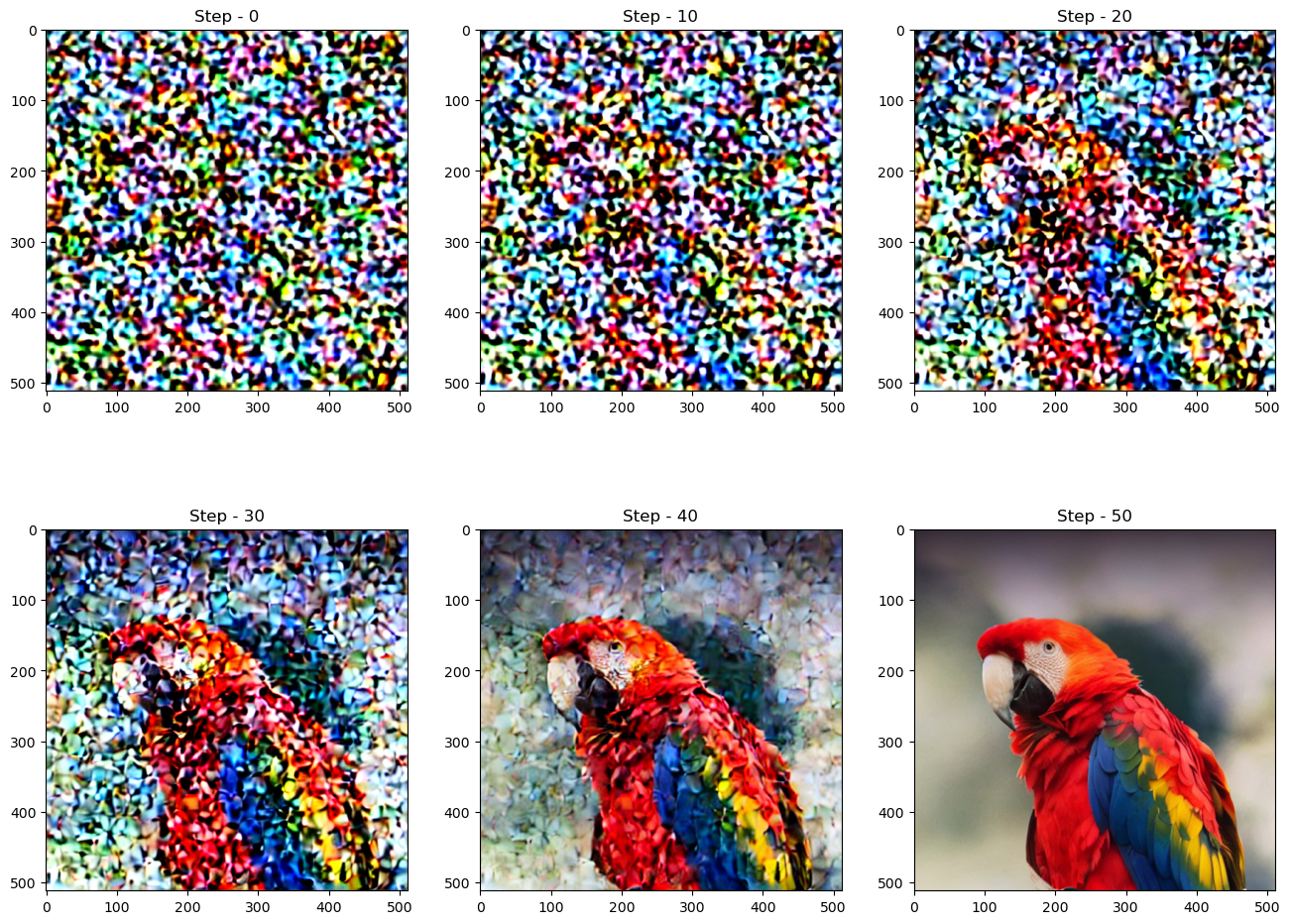
Let’s see how a U-Net removes the noise from the image. Let’s start by adding some noise to the image.
Code
encoded_and_noised = scheduler.add_noise(latent_img, noise, timesteps=torch.tensor([scheduler.timesteps[40]]))
latents_to_pil(encoded_and_noised)[0]
Let’s run through U-Net and try to de-noise this image.
## Unconditional textual prompt
prompt = [""]
## Using clip model to get embeddings
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to("cuda"))[0]
## Using U-Net to predict noise
latent_model_input = torch.cat([encoded_and_noised.to("cuda").float()]).half()
with torch.no_grad():
noise_pred = unet(latent_model_input, 40, encoder_hidden_states=text_embeddings)["sample"]
## Visualize after subtracting noise
latents_to_pil(encoded_and_noised- noise_pred)[0]
As we can see above the U-Net output is clearer than the original noisy input passed.
4.3 What’s their role in the Stable diffusion pipeline
Latent diffusion uses the U-Net to gradually subtract noise in the latent space over several steps to reach the desired output. With each step, the amount of noise added to the latents is reduced till we reach the final de-noised output. U-Nets were first introduced by this paper for Biomedical image segmentation. The U-Net has an encoder and a decoder which are comprised of ResNet blocks. The stable diffusion U-Net also has cross-attention layers to provide them with the ability to condition the output based on the text description provided. The Cross-attention layers are added to both the encoder and the decoder part of the U-Net usually between ResNet blocks. You can learn more about this U-Net architecture here.
5 Conclusion
In this post, we saw the key components of a Stable diffusion pipeline i.e., CLIP Text encoder, VAE, and U-Net. In the next post, we will look at the diffusion process using these components. Read the next part here.
I hope you enjoyed reading it, and feel free to use my code and try it out for generating your images. Also, if there is any feedback on the code or just the blog post, feel free to reach out on LinkedIn or email me at aayushmnit@gmail.com.