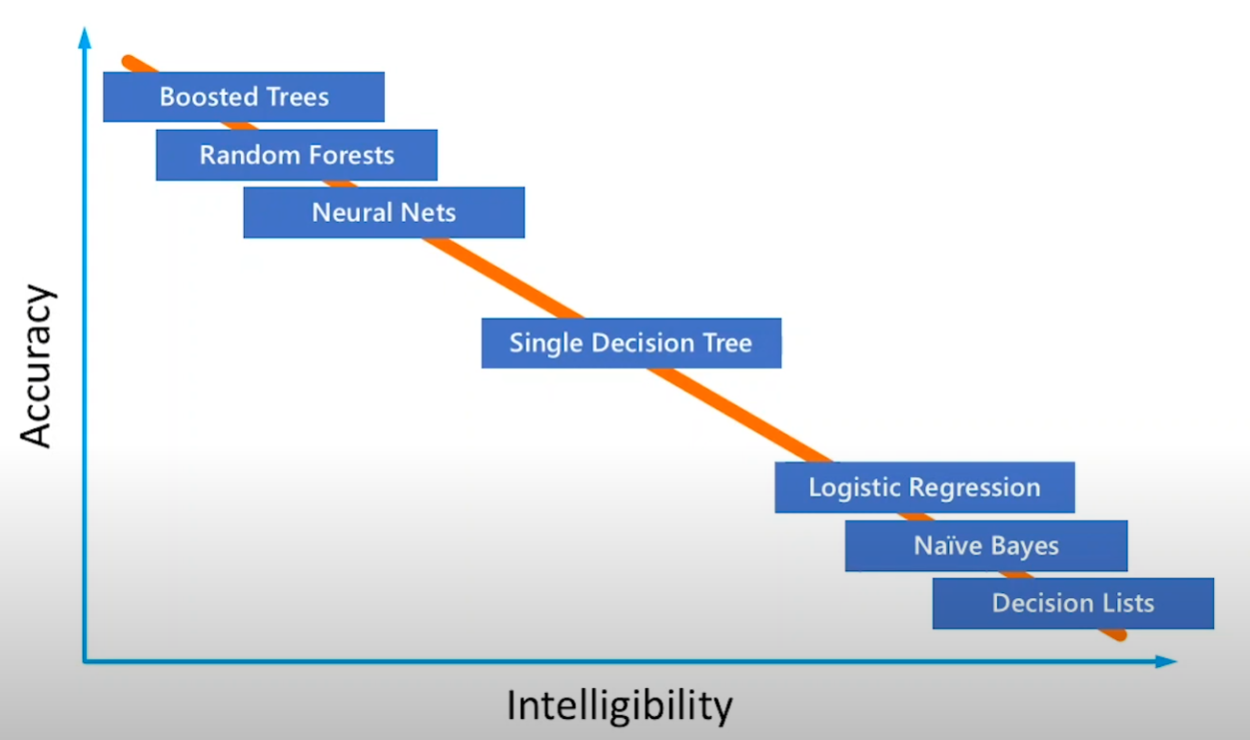
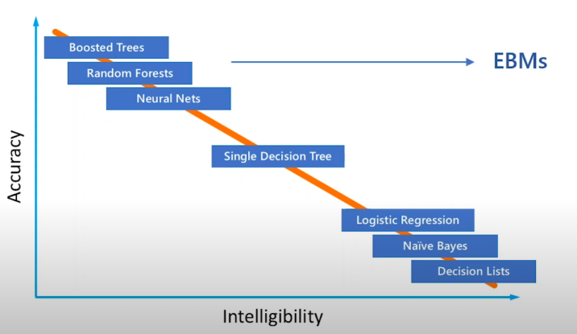
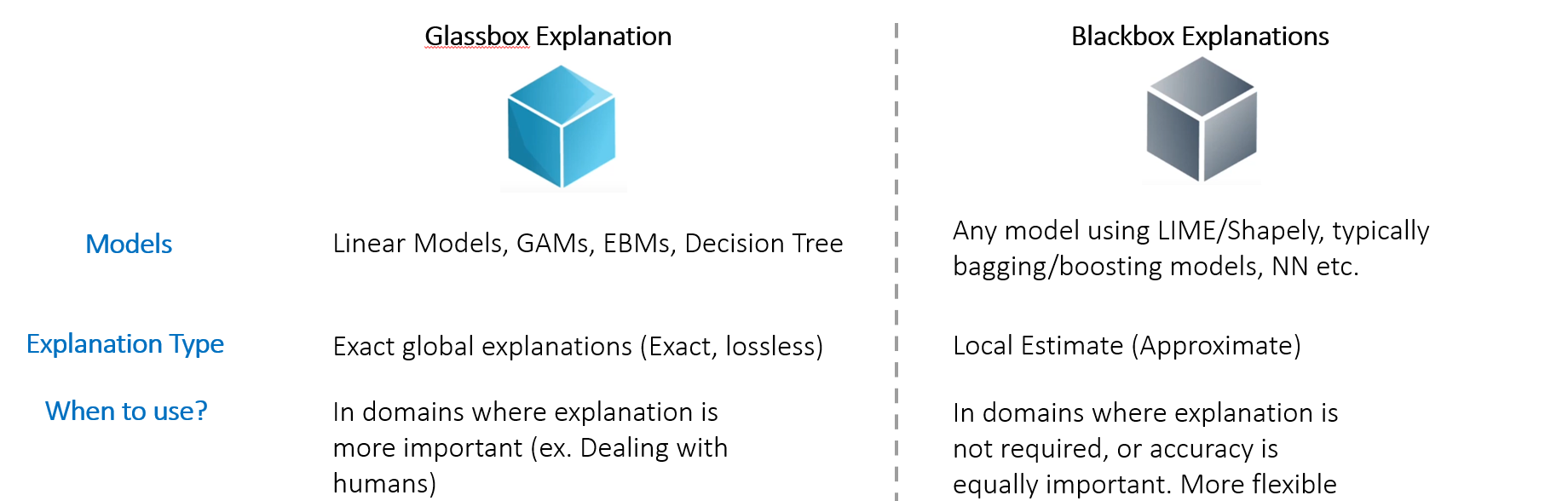
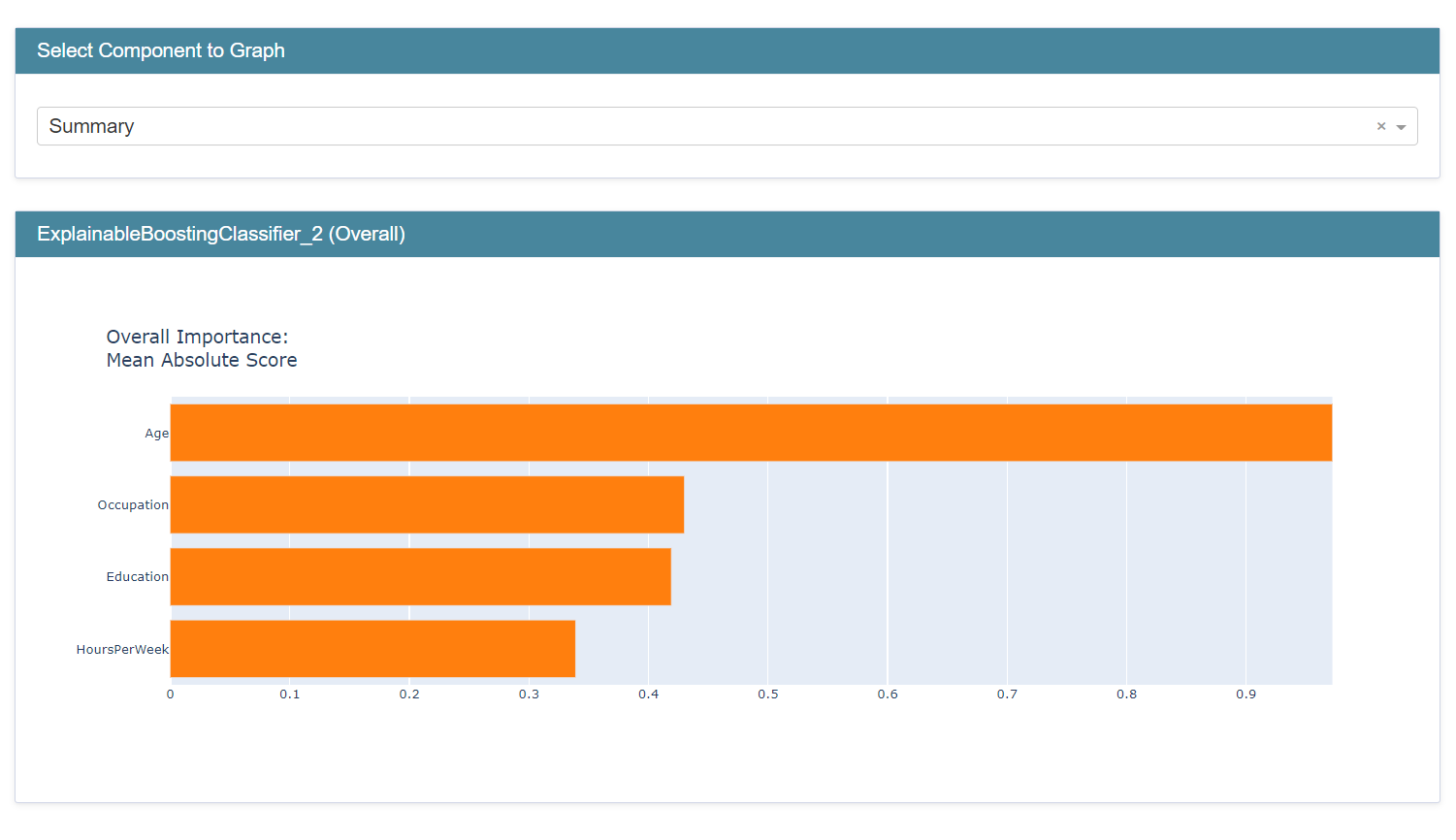
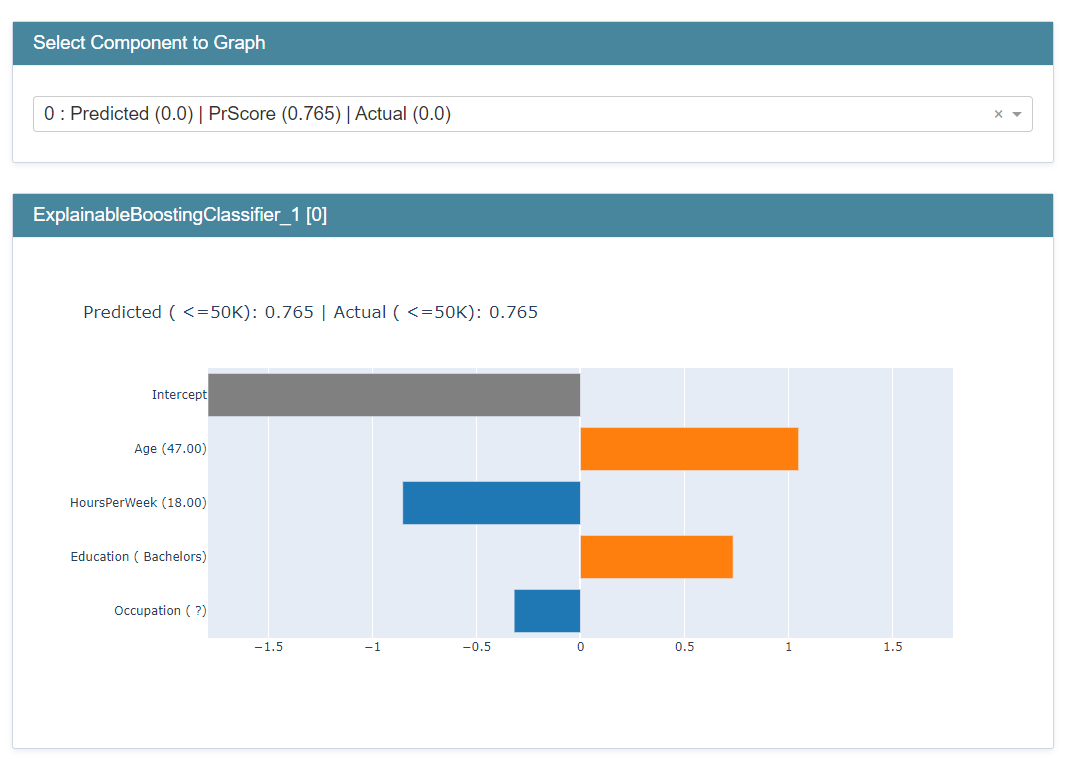
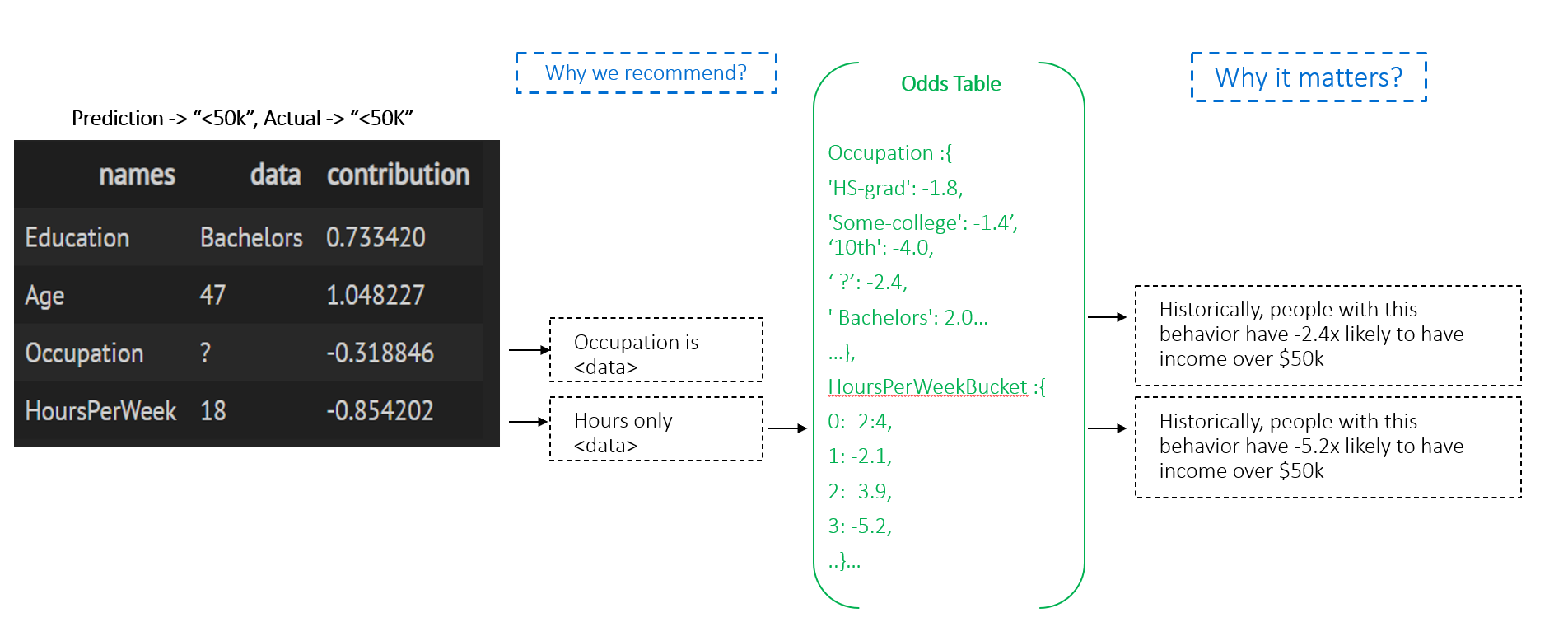
{'Education': {' HS-grad': -1.8, ' Some-college': -1.4, ' 10th': -4.0, ' Masters': 2.5, ' Assoc-voc': 1.1, ' Bachelors': 2.0, ' Assoc-acdm': 1.0, ' 1st-4th': -9.0, ' 11th': -4.7, ' 9th': -4.1, ' Doctorate': 3.1, ' Prof-school': 3.2, ' 12th': -2.9, ' 7th-8th': -3.8, ' 5th-6th': -6.2, ' Preschool': -245.4}, 'AgeBucket': {9: 1.8, 11: 1.5, 7: 1.4, 12: 1.2, 6: -1.1, 10: 1.8, 5: -2.3, 14: -1.2, 8: 1.6, 4: -20.0, 3: -100.0, 15: -1.3, 13: -1.1, 16: -2.1, 18: -2.4, 17: -245.3}, 'HoursPerWeekBucket': {8: -1.2, 9: 1.5, 12: 1.8, 3: -5.2, 7: -1.5, 6: -3.1, 5: -4.7, 10: 2.0, 4: -3.7, 14: 1.6, 2: -3.9, 13: 1.7, 11: 1.9, 15: 1.4, 1: -2.1, 0: -2.4, 19: 1.2, 16: 1.7, 17: 1.1, 18: 1.1}, 'Occupation': {' Machine-op-inspct': -1.8, ' ?': -2.4, ' Other-service': -7.1, ' Craft-repair': -1.0, ' Prof-specialty': 2.1, ' Handlers-cleaners': -3.9, ' Exec-managerial': 2.3, ' Sales': 1.1, ' Adm-clerical': -2.0, ' Transport-moving': -1.2, ' Tech-support': 1.2, ' Protective-serv': 1.4, ' Farming-fishing': -2.0, ' Priv-house-serv': -15.2, ' Armed-Forces': -1.9}}